Motion Profiles
Success Criteria
- Configure a motion system with PID and FeedForward
- Add a trapezoidal motion profile command (runs indefinitely)
- Create a decorated version with exit conditions on reaching the target
- Create a small auto sequence to cycle multiple points
- Create a set of buttons for different setpoints
Synopsis
Motion Profiling is the process of generating smooth, controlled motion. This is typically done using controlled, intermediate setpoints, consideration of the system's physical properties, and other imposed limitations.
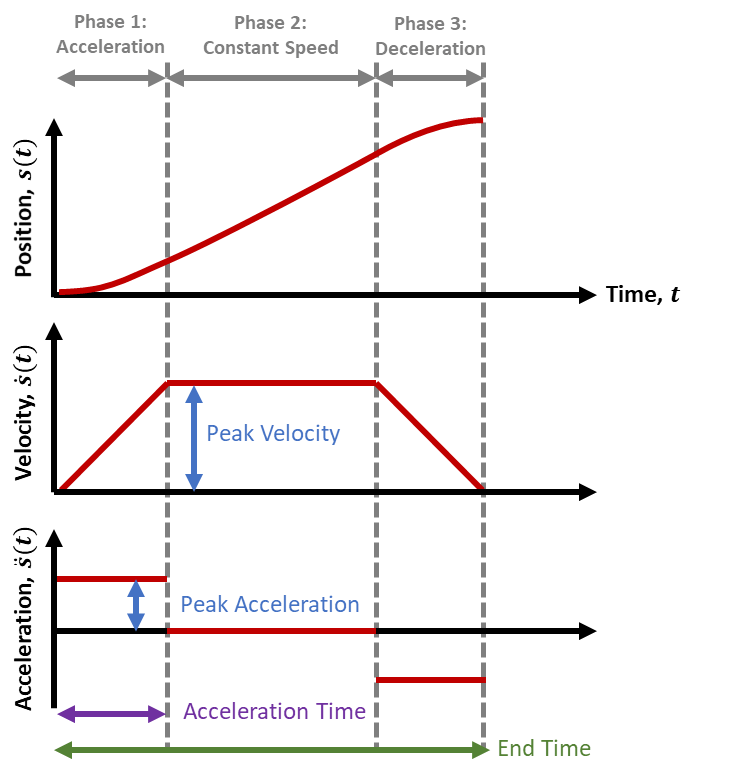
In FRC our tooling generally utilizes a Trapazoidal profile, allowing us precise control of system position, maximum system speed, and acceleration applied to the system.
Benefits of Motion profiling
Motion Profiling resolves several problems that can come up with "simpler" control systems such as simple open loop or straight PID control.
The first comes from acknowledgement of the basic physics equation
The next relates to "tuning": The process of adjusting robot parameters to generate consistent motion. If you've gone through the PID tuning process, you probably remember one struggle: Your tuning works great until you move the setpoint a larger distance, at which point it wildly misbehaves, and the system acts erratically. This case is caused by sharp changes in system error, resulting in the PID generating a large output. Motion profiles instead change the setpoint at a controlled rate, ensuring a small system error keeping the PID in a much more stable state.
The extra complexity is worth it! Tuning a system using a Motion Profile is significantly less work than without it, since all the biggest pain points are eliminated. Your PID behaves better, with no overshoot or sharp outputs, and your system
How it works
For these purposes, we're going to discuss a "positional" control system, such as an Elevator or Arm .
Motion Profiles still apply to velocity control Rollers and Flywheels; In those cases, we ignore the position, smoothly accelerating to our target velocity. This means we only see half the benefit on those systems.
The system we typically use is a "Trapezoidal" profile, named after the shape of the velocity graph it generates.
This system has just two parameters:
- A maximum velocity
- a maximum acceleration.
By having these values set at values the physical system can achieve, our motion profile can split up one large motion into 3 segments.
- An acceleration step, where the motor is approaching the max speed
- Running at our max speed
- Decelerating on approach to the final position.
Because our Motion Profile is aware of our system capabilities, it can then constrain our setpoint changes to ones that that our system can actually achieve, generating a smooth motion without overshooting our final target (or goal).
Since we know how long it takes to accelerate and decelerate, and the max speed, we can also predict exactly how long the whole motion takes!
The entire motion looks just like this:
Finding Max Velocity
A theoretical maximum can be found by multiplying your maximum motor RPM by your gear reduction: It's very similar to configuring your encoder conversion factor, then hitting it with your maximum velocity.
In practice, you normally want to start by setting it slow, at something that you can visually track: Often ~1-2 seconds for a specific range of motion. This helps with testing, since you can see it work and mentally confirm whether it's what you expect.
As you improve and tune your system, you can simply then increase the maximum until your system feels unsafe, and then go back down a bit.
In many practical FRC systems, you may not hit the actual maximum speed of your system: Instead, the system well simply accelerate to the halfway point and then decelerate. This is normal, and simply means the system is constrained by the acceleration.
Finding Max Acceleration
The maximum acceleration effectively represents the actual force we're telling the motor to apply. It's easiest to understand at the extremes:
- When set to zero, your system will never have force applied; It won't move at all.
- When set to infinite, your system assumes it can reach to the max velocity instantly; This is effectively just applying as much force as your system is configured for.
However, in actual systems you want them to move, so zero is useless. And infinite is useful, but impractical: Thinking back to our equation,
This final form helps us clearly see we have a maximum: Our output force is is defined by the motor's max output and our system's mass, giving us a maximum constraint:
Note this is highly simplified: Actually calculating max acceleration this way on real-world systems is often non-trivial, and involves significantly more variables and equations than listed here. However, it's the concept that's important.
In practice, the easiest way to find acceleration is to simply start small increase the acceleration until the system moves how you want. If it starts making concerning noises or over-shooting, then you've gone too far, and you should back it off.
Revisiting the graph
With some background, there's a couple ways to visually interpret this graph:
- This graph always represents the generated profile, but also should reflect your actual position too! When configured correctly, the generated graph is always within our system's capability.
- The calculated "position" setpoint is generally what we feed to our system's PID output.
- The "acceleration" impacts the angle on our velocity trapezoid! At infinite, it's vertical, and at zero, it's horizontal.
Interactions with FeedForwards
Having a motion profile also enables inputs for FeedForwards, allowing even higher levels of precision on your expected outputs.
At the basic level, positional PIDs can be trivially configured with kG and kS, which only depend on values known on all systems. kG is constant or depends on position, and kS depends only on direction of motion.
However, the kV and kA gains both depend on not just on position, but also a known system acceleration and velocity targets.... which we haven't had with arbitrary setpoint jumps.
But now, we can plan our motion: Giving us velocity and acceleration targets. With the right feedforwards, we can now compute the moment-to-moment output for the entire motion in advance!
Interaction with PIDs
The most important part is that our error changes from one big setpoint jump to a lot of small, properly calculated ones.
Without a feed-forward, simply having a motion profile completely removes the big transitions and associated output spikes. This makes tuning simpler, less critical, and often allows for more aggressive PID gains without problems. However, many positional systems will usually still need an I term to accurately hit setpoints accurately without rapid oscillations from a high P term.
With a partial FeedForward (kG + kS) the Feed-Forward handles the base lifting, reducing the need of a PID to handle gravity. This leaves the PID left to handle the motion itself, and it can easily hit setpoint targets without an I term, barring weight changes (such as loaded game pieces)
With a full FeedForward, the error between commanded motion and actual motion will be extremely small, making the PID's impact almost completely irreverent. This makes the PID tuning extremely easy, and the gains can be tuned for precisely the expected disturbances you'll encounter, such as impacts or weight variation.
Note, that despite having theoretically minimal impact, you would still always want a PID to ensure the system gets back to position in cause of error.
Tuning Errors and Adjustments
Fortunately, with motion profiles you get a lot, with very little in the way of potential problems.
Most errors can be easily captured by looking at the position and velocity graph of a real system, and applying a bit of reasoning on what line isn't matching up.
- Overshooting the position setpoint at the end: This likely means your acceleration is too high, or your I gain is too large.
- The system is lagging behind the setpoints and the lines are diverting entirely. It then overshoots the setpoint: Your system cannot output enough power to meet your acceleration constraint. Make sure you have appropriate current limits, and/or lower the acceleration within the system capability.
- The system is lagging behind the setpoints so the lines are parallel but offset: This is typical when not using kA+kV, or when they're set too low. The difference is how long it takes the PID control to kick in and make up for what kA+kV should be generating for that motion.
- The motion is very jerky when travelling at the max speed: This usually means kV is too high, but can be kS being too high. Lowering kP may help as well.
- It starts really awful and smooths out: Likely kA is too high, although again kS and kP can influence this.
Implementing <system type here>
The full system and example code is part of the system descriptions:
The most effective way in general is using the WPILib ProfiledPIDController providing the simplest complete implementation.
This works as a straight upgrade to the standard PID configuration, but takes 2 additional parameters that grant huge performance gains and easier tuning.
ExampleElevator extends SubsystemBase{
SparkMax motor = new SparkMax(42,kBrushless);
//Configure reasonable profile constraints
private final TrapezoidProfile.Constraints constraints =
new TrapezoidProfile.Constraints(kMaxVelocity, kMaxAcceleration);
//Create a PID that obeys those constraints in it's motion
//Likely, you will have kI=0 and kD=0
//Note, the unit of our PID will need to be in Volts now.
private final ProfiledPIDController controller =
new ProfiledPIDController(kP, kI, kD, constraints, 0.02);
//Our feedforward object appropriate for our subsystem of choice
//When in doubt, set these to zero (equivilent to no feedforward)
//Will be calculated as part of our tuning.
private final ElevatorFeedforward feedforward =
new ElevatorFeedforward(kS, kG, kV);
//Lastly, we actually use our new
public Command setHeight(Supplier<Distance> position){
return run(
()->{
//Update our goal with any new targets
controller.setGoal(position.get().in(Inches));
//Calculate the voltage
voltage=
motor.setVoltage(
controller.calculate(motor.getEncoder().getPosition())
+ feedforward.calculate(controller.getSetpoint().velocity)
);
});
}
The big difference compared to our other, simpler PID is that we're using motor.setVoltage for this; This relates to the inclusion of FeedForwards which prefers volts for improved consistency as the battery drains.
While the PID itself doesn't care, since we're adding them together they do need to be the same unit.
If you already calculated your PID gains using motor.set() or
Basic Telemetry
Goals
Understand how to efficiently communicate to and from a robot for diagnostics and control
Success Criteria
- Print a notable event using the RioLog
- Find your logged event using DriverStation
- Plot some sensor data (such as an encoder reading), and view it on Glass/Elastic
- Create a subfolder containing several subsystem data points.
As a telemetry task, success is thus open ended, and should just be part of your development process; The actual feature can be anything, but a few examples we've seen before are
Why you care about good telemetry
By definition, a program runs exactly as you the code was written to run. Most notably, this does not strictly mean the code runs as it was intended to.
When looking at a robot, there's a bunch of factors that can have be set in ways that were not anticipated, resulting in unexpected behavior.
Telemetry helps you see the bot as the bot sees itself, making it much easier to bridge the gap between what it's doing and what it should be doing.
Printing + Logging
Simply printing information to a terminal is often the easiest form of telemetry to write, but rarely the easiest one to use. Because all print operations go through the same output interface, the more information you print, the harder it is to manage.
This approach is best used for low-frequency information, especially if you care about quickly accessing the record over time. It's best used for marking notable changes in the system: Completion of tasks, critical events, or errors that pop up. Because of this, it's highly associated with "logging".
The methods to print are attached to the particular print channels
//System.out is the normal output channel
System.out.println("string here"); //Print a string
System.out.println(764.3); //you can print numbers, variables, and many other objects
//There's also other methods to handle complex formatting....
//But we aren't too interested in these in general.
System.out.printf("Value of thing: %n \n", 12);
A typical way this would be used would be something like this:
public ExampleSubsystem{
boolean isAGamePieceLoaded=false;
boolean wasAGamePieceLoadedLastCycle=false;
public Command load(){
//Some operation to load a game piece and run set the loaded state
return runOnce(()->isAGamePieceLoaded=true);
}
public void periodic(){
if(isAGamePieceLoaded==true && wasAGamePieceLoadedLastCycle==false){
System.out.print("Game piece now loaded!");
}
if(isAGamePieceLoaded==false && wasAGamePieceLoadedLastCycle==true){
System.out.print("Game piece no longer loaded");
}
wasAGamePieceLoadedLastCycle=isAGamePieceLoaded
}
}
Rather than spamming "GAME PIECE LOADED" 50 times a second for however long a game piece is in the bot, this pattern cleanly captures the changes when a piece is loaded or unloaded.
In a more typical Command based robot , you could put print statements like this in the end() operation of your command, making it even easier and cleaner.
The typical interface for reading print statements is the RioLog: You can access this via the Command Pallet (CTRL+Shift+P) by just typing > WPILIB: Start Riolog. You may need to connect to the robot first.
These print statements also show up in the DriverStation logs viewer, making it easier to pair your printed events with other driver-station and match events.
NetworkTables
Data in our other telemetry applications uses the NetworkTables interface, with the typical easy access mode being the SmartDashboard api. This uses a "key" or name for the data, along with the value. There's a couple function names for different data types you can interact with
// Put information into the table
SmartDashboard.putNumber("key",0); // Any numerical types like int or float
SmartDashboard.putString("key","value");
SmartDashboard.putBoolean("key",false);
SmartDashboard.putData("key",field2d); //Many built-in WPILIB classes have special support for publishing
You can also "get" values from the dashboard, which is useful for on-robot networking with devices like Limelight, PhotonVision, or for certain remote interactions and non-volatile storage.
Note, that since it's possible you could request a key that doesn't exist, all these functions require a "default" value; If the value you're looking for is missing, it'll just give you the provided default.
SmartDashboard.getNumber("key",0);
SmartDashboard.getString("key","not found");
SmartDashboard.getBoolean("key",false);
Networktables also supports hierarchies using the "/" seperator: This allows you to separate things nicely, and the telemetry tools will let you interface with groups of values.
SmartDashboard.putNumber("SystemA/angle",0);
SmartDashboard.putNumber("SystemA/height",0);
SmartDashboard.putNumber("SystemA/distance",0);
SmartDashboard.putNumber("SystemB/angle",0);
While not critical, it is also helpful to recognize that within their appropriate heirarchy, keys are displayed in alphabetical order! Naming things can thus be helpful to organizing and grouping data.
Good Organization -> Faster debugging
As you can imagine, with multiple people each trying to get robot diagnostics, this can get very cluttered. There's a few good ways to make good use of Glass for rapid diagnostics:
- Group your keys using
group/key. All items with the samegroup/value get put into the same subfolder, and easier to track. Often subsystem names make a great group pairing, but if you're tracking something specific, making a new group can help. - Label keys with units: a key called
angleis best when written asangle degree; This ensures you and others don't confuse it withangle rad. - Once you have your grouping and units, add more values! Especially when you have multiple values that should be the same. One of the most frequent ways for a system to go wrong is when two values differ, but shouldn't.
A good case study is an arm: You would have
- An absolute encoder angle
- the relative encoder angle
- The target angle
- motor output
And you would likely have a lot of other systems going on. So, for the arm you would want to organize things something like this
SmartDashboard.putNumber("arm/enc Abs(deg)",absEncoder.getAngle());
SmartDashboard.putNumber("arm/enc Rel(deg)",encoder.getAngle());
SmartDashboard.putNumber("arm/target(deg)",targetAngle);
SmartDashboard.putNumber("arm/output(%)",motor.getAppliedOutput());
A good sanity check is to think "if someone else were to read this, could they figure it out without digging in the code". If the answer is no, add a bit more info.
Glass
Glass is our preferred telemetry interface as programmers: It offers great flexibility, easy tracking of many potential outputs, and is relatively easy to use.
Glass does not natively "log" data that it handles though; This makes it great for realtime diagnostics, but is not a great logging solution for tracking data mid-match.
This is a great intro to how to get started with Glass:
https://docs.wpilib.org/en/stable/docs/software/dashboards/glass/index.html
For the most part, you'll be interacting with the NetworkTables block, and adding visual widgets using Plot and the NetworkTables menu item.
Elastic
Elastic is a telemetry interface oriented more for drivers, but can be useful for programming and other diagnostics. Elastic excels at providing a flexible UI with good at-a-glance visuals for various numbers and directions.
Detailed docs are available here:
https://frc-elastic.gitbook.io/docs
As a driver tool, it's good practice to set up your drivers with a screen according to their preferences, and then make sure to keep it uncluttered. You can go to Edit -> Lock Layout to prevent unexpected changes.
For programming utility, open a new tab, and add widgets and items.
Plotting Data
Physics Simulation
Success Criteria
- Create a standard Arm or Elevator
- Model the system as a Mechanism2D
- Create a Physics model class
- Configure the physics model
- Tune the model to react in a sensible way. It does not need to match a real world model
Brief rundown of some code
Basic Odometry+Telemetry
Synopsis
Success Criteria
- Create a Widget on a dashboard to show the field
- Populate the Field with your robot, and one or more targets
- Utilize the Field to help develop a "useful feature" displayed on the Field
As a telemetry task, success is thus open ended, and should just be part of your development process; The actual feature can be anything, but a few examples we've seen before are
- showing which of several targets your code has deemed best, and react to it
- a path your robot is following, and where the bot is while following it
- The current Vision targets and where your bot is when seeing them
- A field position used as an adjustable target
- The projected path for a selected auto
- Inidcate proximity or zones "zones" for performing a task, such as the acceptable range for a shooting task or intaking process.
Odometry Fundamentals
Odometry is also known as Position Tracking. In FRC, this is generally regarded as knowing the position of your robot in the game field. It is most beneficial when combined with the robot to then have the robot move between positions on the field, and interact with other known positions.
Actually obtaining odometry depends on the design of the bot: Differential Drive Odometry or Swerve Odometry , and often involves vision systems via LimeLight Odometry or PhotonVision Odometry
This document is concerned with the prerequisite: Being able to actually view, compare, and validate positions using robot telemetry.
Odometry Telemetry
Telemetry for Odometry revolves around the Field2D object. Both Glass and Elastic can display the Field2D object as a game field on the dashboard, including associated robot positions and any secondary objects.
In general, Glass is the superior option for most programming tasks and development, allowing easier customization to help reduce clutter and provide clarity between objects.
The WPILib Docs are excellent at helping demonstrate many of these examples:
https://docs.wpilib.org/en/stable/docs/software/dashboards/glass/field2d-widget.html
Pose
In Robots, a Pose represents a specific location and state of a robot's actuator. Within the context of odometry, a pose represents the robot's location on a 2D plane. In most cases, this means the location on the game field.
In order to represent such a state, we need 3 things: The X position, the Y position, and a rotation.
In WPILib, this is handled by the Pose2d object, which can be provided to and returned from many utilities interacting with the robot position, including drivetrain path planning, vision, simulation, and telemetry.
Field2D Basics
The Field2D object in WPILib contains a number of utilities for keeping tabs on odometry. It can be added with just a couple lines.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
//We only want to send the actual Field object _once_,
//so we often do it in the constructor. Changes will be
//sent automatically as the Field2d object itself is updated.
//Preferred: Set the NetworkTables name explicitly,
//and give it a unique, descriptive name
SmartDashboard.putData("ChassisField",field);
// This form uses the default name "Field" as the key.
// Not recommended in most cases
//SmartDashboard.putData(field);
}
}
This creates a blank, empty field, with your robot position, probably at (0,0) in the bottom left corner, on the blue side of the field.
Meaningfully updating the robot pose is out of scope, and differs by drivetrain type; However, the basic gist is
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
//Set up an odometry object to track our robot
DifferentialDrivePoseEstimator odometry=new DifferentialDrivePoseEstimator(
/* Complex constructor parameters; not relevant*/
)
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
}
public void periodic(){
//Read the odometry object and set the pose. //Reference only
field.setRobotPose(odometry.getPoseMeters());
// Or, we can just set it manually for testing.
field.setRobotPose(new Pose2d(2.7,3.1, new Rotation2d(Math.PI/2.0) ));
}
}
Now, when we open our Field2D widget in Glass, we'll see that our robot is at a new position. If we fully implemented our Pose Estimator object, we'd see that this provides realtime tracking of our position.
A .getRobotPose() also exists, but tends to be less useful in practice, as most classes that will interact with the Robot and Field will likely have access to the Odometry object directly.
Note, that the Field2d object we create is a unique reference, with it's own unique local data; only the NetworkTables key might have overlap when using default keys. This means if we want to properly share a Field across multiple classes, we either need to fetch the NetworkTables data and copy it over, create a single Field object in RobotContainer and pass it to, or create a DriverField object as a Singleton that can facilitate a single object.
Displaying Useful Targets
Where Field2d objects really shine is in adding supplemental information about other field objects. The utility varies by game, but it's great for showing a variety of things such as
- Targets/objectives
- Nearest/best target
- Nearest game piece (detected by vision systems)
These can be done using the getObject(name) method; This grabs the named object from the field, creating it if it doesn't already exist.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
}
public void periodic(){
//Can provide any number of pose arguments
field.getObject("GamePieces").setPoses(
new Pose2d(1,1),
new Pose2d(1,2),
new Pose2d(1,3),
);
//You can also pass a single List<Pose2d>
//if you have a list of poses already
field.getObject("BestGamePiece").setPose(
new Pose2d(1,2)
);
}
}
Note It's worth considering that for objects that never move, you could set objects once in the constructor, and they work fine. However, if the user accidentally moves them in the UI, it creates a visual mis-match between what the code is doing and what the user sees. As a result, it's often better to just throw it in a Periodic.
Field2d + User Input
A niche, but very useful application of field objects is to get precise driver feedback on field location data. This can be done using the following code setup:
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
//Set the pose exactly once at boot
field.getObject("DriverTarget").setPose(
new Pose2d(1,2)
);
}
public Command aimAtCustomTarget(){
return run(()->{
var target=field.getObject("DriverTarget").getPose();
//Do math to figure out the angle to target
//Set your drivetrain to face the target
};
}
public void periodic(){
//No setting DriverTarget pose here!
};
}
In this case, we take advantage of the "set once" approach in constructors; The drivers or programmers can modify the position, and then we now read it back into the code.
This can be very useful for testing to create "moving targets" to test dynamic behavior without having to drive the bot. It can also help you create "simulation" poses for testing math relating to Pose2D objects.
is especially true for simulation, as this allows you quickly test pose-related functions and makes sure that things happen how you expect.
One practical application is match-specific targets for cooperating with allies. An example is in 2024 Crescendo: a common game tactic was to "pass" rings across the field, by shooting to an open area near where your allies would be. However, since the game pieces can get stuck in/on robots, and different robots have different intakes, and each ally has different sight lines, making the ideal pass target unknown until the actual match is about to start. An adjustable target let the alliance sort it out before a match without having to change the code.
Displaying Paths
When doing path-planning for drivetrains, it's often helpful to display the full intended path, rather than a lot of individual poses.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
//Set the pose exactly once at boot
field.getObject("DriverTarget").setPose(
new Pose2d(1,2)
);
}
public Command buildAuto1(){
var trajectory=// Get the trajectory object from your path tool
field.getObject("autoTrajectory").setTrajectory(trajectory);
return run(()->{
//draw the rest of the owl
};
}
}
In this use case, the work will likely be done inside your Auto class after selecting the appropriate one.
Git Basics
Goals
Understand the typical Git operations most helpful for day-to-day programming
Completion Requirements
This module is intended to be completed alongside other tasks: Learning Git is best done by doing, and doing requires having code to commit.
- Read through the Git Fundamentals section
- Initialize a git repository in your project
- Create an initial commit
- Create several commits representing simple milestones in your project
- When moving to a new skill card, create a new branch to represent it. Create as many commits on the new branch as necessary to track your work for this card.
- When working on a skill card that does not rely on the previous branch, switch to your
mainbranch, and create a new branch to represent that card. - On completion of that card (or card sequence), merge the results of both branches back into Main.
- Upon resolving the merge, ensure both features work as intended.
Topic Summary
- Understanding git
- workspace, staging, remotes
- fetching
- Branches + commits
- Pushing and pulling
- Switching branches
- Merging
- Merge conflicts and resolution
- Terminals vs integrated UI tools
Git Fundamentals
Git is a "source control" tool intended to help you manage source code and other text data.
Git has a lot of utility, but the core concept is that git allows you to easily capture your files at a specific point in time. This allows you to see how your code changes over time, do some time travel to see how it used to look, or just see what stuff you've added since your last snapshot.
Git does this by specifically managing the changes to your code, known as "commits". These build on each other, forming a chain from the start of project to the current code.
At the simplest, your project's history something like the following
Git is very powerful and flexible, but don't be intimidated! The most valuable parts of git are hidden behind just a few simple commands, and the complicated parts you'll rarely run into. Bug understanding how it works in concept lets you leverage it's value better.
Diffs
Fundamental to Git is the concept of a "difference", or a diff for short. Rather than just duplicating your entire project each time you want to make a commit snapshot, Git actually just keeps track of only what you've changed.
In a simplified view, updating this simple subsystem
/**Example class that does a thing*/
class ExampleSubsystem extends SubsystemBase{
private SparkMax motor = new SparkMax(1);
ExampleSubsystem(){}
public void runMotor(){
motor.run(1);
}
public void stop(){/*bat country*/}
public void go(){/*fish*/}
public void reverse(){/*shows uno card*/}
}
to this
/**Example class that does a thing*/
class ExampleSubsystem extends SubsystemBase{
private SparkMax motor = new SparkMax(1);
private Encoder encoder = new Encoder();
ExampleSubsystem(){}
public void runMotor(double power){
motor.run(power);
}
public void stop(){/*bat country*/}
public void go(){/*fish*/}
public void reverse(){/*shows uno card*/}
}
would be stored in Git as
class ExampleSubsystem extends SubsystemBase{
private SparkMax motor = new SparkMax(1);
+ private Encoder encoder = new Encoder();
ExampleSubsystem(){}
- public void runMotor(1){
- motor.run(1);
+ public void runMotor(double power){
+ motor.run(power);
}
public void stop(){/*bat country*/}
With this difference, the changes we made are a bit more obvious. We can see precisely what we changed, and where we changed it.
We also see that some stuff is missing in our diff: the first comment is gone, and we don't see go(), reverse() or our closing brace. Those didn't change, so we don't need them in the commit.
However, there are some unchanged lines, near the changed lines. Git refers to these as "context". These help Git figure out what to do in some complex operations later. It's also helpful for us humans just taking a casual peek at things. As the name implies, it helps you figure out the context of that change.
We also see something interesting: When we "change" a line, Git actually
- Marks it as deleted
- adds a new line that's almost the same
Simply put, just removing a line and then adding the new one is just easier most of the time. However, some tools detect this, and will bold or highlight the specific bits of the line that changed.
When dealing with whole files, it's basically the same! The "change" is the addition of the file contents, or a line-by-line deletion of them!
Commits + Branches
Now that we have some changes in place, we want to "Commit" that change to Git, adding it to our project's history.
A commit in git is a just a collection of smaller changes, along with some extra data for keeping track. The most relevant is
- A commit "hash", which is a unique key representing that specific change set
- The "parent" commit, which these changes are based on
- The actual changes + files they belong to.
- Date, time, and author information
- A short human readable "description" of the commit.
These commits form a sequence, building on top from the earliest state of the project. We generally assign a name to these sequences, called "branches".
A typical project starts on the "main" branch, after a few commits, you'll end up with a nice, simple history like this.
It's worth noting that a branch really is just a name that points to a commit, and is mostly a helpful book-keeping feature. The commits and commit chain do all the heavy lifting. Basically anything you can do with a branch can be done with a commit's hash instead if you need to!
Multiple Branches + Switching
We're now starting to get into Git's superpowers. You're not limited to just one branch. You can create new branches, switch to them, and then commit, to create commit chains that look like this:
Here we can see that mess for qual 4 and mess for qual 8 are built off the main branch, but kept as part of the competition branch. This means our main branch is untouched. We can now switch back and forth using git switch main and git switch competition to access the different states of our codebase.
We can, in fact, even continue working on main adding commits like normal.
Being able to have multiple branches like this is a foundational part of how Git's utility, and a key detail of it's collaborative model. This is more traditionally referred to as a "git tree", since we can see it starts from a single trunk and then branches out into all these other branches.
However, you might notice the problem: We currently can access the changes in competition or main, but not both at once.
Merging
Merging is what allows us to do that. It's helpful to think of merging the commits+changes from another branch into your current branch.
If we merge competition into main, we get this. Both changes ready to go! Now main can access the competition branch's changes.
However, we can equally do main into competition, granting competition access to the changes from main.
Now that merging is a tool, we have unlocked the true power of git. Any set of changes is built on top of each other, and we can grab changes without interrupting our existing code and any other changes we've been making!
This feature powers git's collaborative nature: You can pull in changes made by other people just as easily as you can your own. They just have to have the same parent somewhere up the chain so git can figure out how to step through the sequence of changes.
Workspace, Staging, and Commits
When managing changes, there's a couple places where they actually live.
The most apparent one is your actual code visible on your computer, forming the "Workspace". As far as you're concerned, this is just the files in the directory, or as seen by VSCode. However, Git sees them as the end result of all changes committed in the current branch, plus any additional, uncommitted changes.
The next one is "staging": This is just the next commit, but in an incomplete state. When setting up a commit, staging is where things are held in the meantime. Once you complete a commit, the staging area is cleared, and the changes are moved to a proper commit in your git tree.
Staging is not quite a commit, as the changes represented here can be easily over-written by staging new changes from your Workspace. But, it's not quite the workspace either, and doesn't automatically follow modifications to your code.
Because of this, Staging is extremely useful for code review! Staging a specific change is a great way to assert that that part is working and tested, even if you're not ready to make a commit yet.
In terms of our usual git tree, Staging and Workspace fit in right at the end, like so.
Lastly, is the actual commits that form your history. We generally won't deal with them individually, and instead just bundle them up in "branch". A branch is is just a helpful shorthand that names a specific commit, but in practice is used to refer to all prior changes leading up to that current commit.
Remotes + Github
Git is a distributed system, and intentionally designed so that code can be split up and live in a lot of different places at once, but interact with each other in sensible ways for managing the code.
The most obvious place it lives is your computer. You have a full copy of the git tree, plus your own staging and workspace. This is often called the "local" repository.
Next is a "remote" repository, representing a remote git server. Often this is Github, using the default remote name of "origin".
The important consideration is that your computer operates totally independently of the remote unless you intend to interact with it! This means you can do almost any Git task offline, and don't even need a remote to make use of Git.
Of course, being set up this way means that if you're not paying attention, you might not catch differences between Remote and Local git states. It's rarely an actual problem, but can be confusing and result in extra work. It's good practice to be aware of where your code is relative to origin, and make sure you push your code up to it when appropriate.
When the origin is indicated specifically, you'll see it shown before the branch name: Main would go from main -> origin/main, like you see here in Git Graph, showing that we have 1 commit locally that doesn't exist on the origin. Or, we're ahead by one commit.
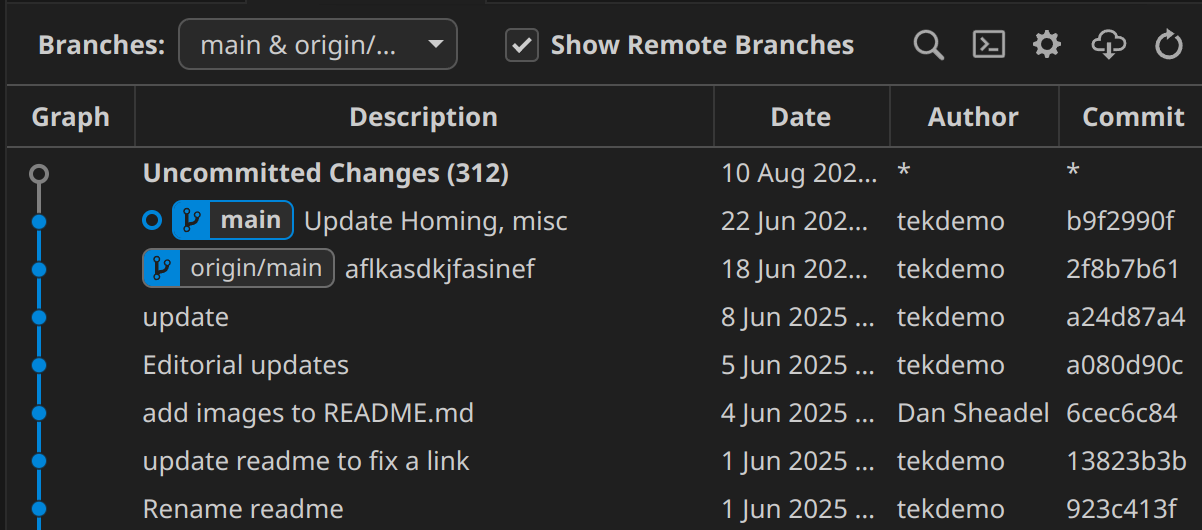
Handling Merge Conflicts
Often when doing merges, you'll run into a "merge conflict", and some parts of your code get replaced with massive compiler errors and weird syntax. Don't panic!
Merge conflicts happen when two branches change the same code. Git can't figure out what the "right answer" is, and so it needs a helping hand. To facilitate this, it has some special syntax so that you can see all information at a glance, but it's not always obvious that it's just being helpful!
Let's look at the simplest possible merge conflict: Being in main, and merging dessert
From an original file containing
Best food is pizza
The commit in main has the following change
-Best food is pizza
+Best food is salad
with dessert having this change
-Best food is pizza
+Best food is cheesecake
The merge is then making Git decide what's the optimal food. Git is not equipped for this debate, so it's up to us humans. Git prepares the file in question using "merge markers" around the issue, which provide some useful info to resolve it
<<<<<<< HEAD
Best food is salad
=======
Best food is cheesecake
>>>>>>> dessert
<<<<<<< HEAD -> indicates the start of a merge conflict. HEAD just means "last commit on current branch". Since we're on main, that means this code is just the result of following the code along the Main branch. VSCode will add additional information above this to help clarify.
>>>>>>> dessert -> is the end of merge conflict. dessert is the branch you're merging from; In other words, it's the result of following the proposed changes along the cheesecake branch. Again, VSCode will add additional info to help.
======= -> is the separator between the two branches' code.
It's helpful to remember the goal of a merge: To put the two codebases together in a way that makes sense and is correct! So a merge conflict is resolved by making code that works, meaning there's several different ways to fix it!
One option is just accepting the change in your current branch, yielding
Best food is salad
This just means you've ignored the proposed change from the other branch (dessert in this case)
The other option is accept the incoming change, and ignore what your branch had.
Best food is cheesecake
In some cases it's both! Maybe you're just fine with two best foods.
Best food is salad
Best food is cheesecake
Of course, you're after correctness. It's possible that after the update neither branch is quite right, and you have to adjust both.
Best side dish is salad
Best dessert is cheesecake
Or, it could be neither! Maybe the right solution has become something else entirely.
Best food is breakfast burritos
Most of the time, a merge conflict should be very easy to deal with if you know the parts of the code you're working with.
Just move the code around until it works like both branches expected, then delete the merge marker, separator, and any unnecessary code, and you're good to go!
And, don't worry if you missed one! Git will spot these conflict markers if you try to commit one without sorting it out.
If you get lost, ask for help! When dealing with code someone else wrote, you simply might not know what the best option is when coming out of it. That's fine! No tool can replace good communication.
Handling Compile errors caused by merges
Merge conflicts aside, just because a merge didn't have a conflict, doesn't mean the code works. A sometimes surprising result stems from the fact that Git doesn't understand code, it just understands changes!
The most likely reason you'll see this is someone changing a function name in one branch, while the other branch adds a new occurrence of it. Let's consider adding this code in our current branch
@@ MainBranch: RobotContainer.java @@
//filecontext
+ exampleSubsystem.callSomeFunction();
//filecontext
and merging in this change from another branch.
@@ CleanupBranch: ExampleSubsystem.java @@
//filecontext
- public void callSomeFunction(){
+ public void betterNamedFunction(){
//filecontext
In this case, main doesn't know about the name change, and CleanupBranch doesn't know that you added a new call to it. This means callSomeFunction() no longer exists, leading to an error.
As with merge conflicts, it's up to you to figure out what's correct. In cases like this, you just want to adjust your new code to use the new name. But it sometimes happens that the other branch did something that needs to be changed back, such as deleting a function no one was using... until now you're using it.
Again, the purpose of the merge is to make it work! You're not done with a merge until everything works together as intended.
The critical Git commands
A lot of Git's power boils down to just using the simple usage of a few basic commands.
While using the command line is optional, most good Git tools retain the name of these operations in graphical interfaces. After all, they're using the same operations behind the scenes.
Because of this, a bit of command line knowledge can help clarify what the more user-friendly tools are trying to do, and show you exactly why they're helpful.
Creating a new repository
git init will creates a new git repository for your current project. It sets the "project root" as the current folder, so you'll want to double-check to make sure you're in the right spot!
VSCode's built in terminal will default to the right folder, so generally if your code compiles, you should be in the right spot. Once the repository is created, git commands will work just fine from anywhere inside your project.
Getting Status
Knowing what your code is up to is step 1 of git. These commands
git status just prints out the current repo status, highlighting what files are staged, and what have unstaged changes, and where you are relative to your remote. If you've used other git commands, the effects will show up in git status. Run it all the time!
git log will open a small terminal dialogue walking you through changes in your branch (hit q to exit). However, it's often unhelpful; It contains a lot of data you don't care about, and is missing clarity on ones you do.
git log --oneline tends to be more helpful ; This just prints a one-line version of relevant commits, making it much more useful.
Adding Changes to build a commit
git add <files> is all that's needed in most cases: This will add all changes present in a specific file.
git add <directories> works too! This adds all changes below the specified folder path. Be mindful to not add stuff you don't want to commit though! Depending on the project and setup, you may or may not want to add all files this way.
git add . is a special case you'll often see in git documentation; . is just a shorthand for "the current folder" . Most documentation uses this to indicate "Stage the entire project", and is mostly helpful for your very first commit. Afterwards, we'd recommend a more careful workflow.
git reset <staged file/dir> will will remove a file's changes from Staging and put them back in the Workspace ; Meaning, the change itself is preserved, but it won't be changed. In practice, you probably won't do this much, as it's easier to use a GUI for this.
Confirming a commit
git commit -m "describe changes here" tends to be the beginner friendly approach. This makes a new commit with any staged changes.
git commit will usually open a small terminal editor called Vim with commit information and let you type a commit message. However, this editor is famous for it's "modal" interface, which is often surprising to work with at first. We'll generally avoid using it in favor of VSCode's commit tooling.
If you get caught using the Vim editor for a commit, this is a quick rundown of the critical interaction.
escape key-> undo whatever command you're doing, and and exit any modes. Mash if you're panicking.
i -> When not in any mode, enter Insert mode (INSERT will be shown at the bottom). You can then type normally. Hit escape to go back to "command mode"
: -> start a command string; Letters following it are part of an editor command.
:w -> Run a write command (this saves your document)
:q -> Run a quit command (exit the file). This will throw an error if you have unsaved changes.
:q! -> The ! will tell Vim to just ignore warnings and leave. This is also the "panic quit" option.
:wq -> Runs "save" and then "quit" using a single command
This means the typical interaction is i (to enter insert mode), type the message, escape, then :wq to save and quit.
You can also abandon a commit by escape + :q!, since an empty commit message is not allowed by default.
Creating Branches
git branch NameOfNewBranch: This just makes a new branch with the current name. Note, it does not switch to it! You'd want to do that before trying to do any commits!
Note, the parent node is the last commit of your current branch; This is not usually surprising if you're working solo, but for group projects you probably want to make sure your local branch is up to date with the remote!
Switching Branches
git switch NameOfBranch: This one's pretty simple! It switches to the target branch.
git switch --detach <commithash> : This lets you see the code at a particular point in time. Sometimes this can be useful for diagnosing issues, or if you want to change where you're starting a new branch (maybe right before a merge or something). --detach just means you're not at the most recent commit of a branch.
You might see git checkout NameOfBranch in some documentation; This is a common convention to "check out" a branch. However, the git checkout command can do a lot of other stuff too. For what we need, git switch tends to be less error prone.
Note, Git will sometimes block you from changing branches! This happens if you have uncommitted changes that will conflict with the changes in the new branch. It's a special kind of merge conflict.
Git has a number of tools to work around this, but generally, there's a few simpler options, depending on the code in question
- Delete/undo the changes: This is a good option if the changes are inconsequential such as accidental whitespace changes, temporarily commented out code for testing, or "junk" changes. Just tidy up and get rid of stuff that shouldn't be there.
- Clean up and commit the changes: This is ideal if the changes belong to the current branch, and you just forgot them previously
- "Work in progress" commit: If you can't delete something, and it's not ready for a proper commit, just create a commit with message beginning with "WIP"; This way, it's clear to you and others that the work wasn't done, and to not use this code.
- use "git stash" the changes: This is git's "proper" resolution for this, but the workflow can be complicated, easy to mess up, and it's out of scope for this document. We won't use it often.
Merging code
git merge otherBranchName : This grabs the commits from another branch, and starts applying them to your current branch. Think of it as merging those changes into yours. If successful, it creates a merge commit for you.
git merge otherBranchName --no-commit : This does the merge, but doesn't automatically make a commit even when successful! This is often preferable, and makes checking and cleanup a bit easier. Once you've ran it, you can finish the commit in the usual way with git commit
git merge --abort is a useful tool too! If your merge is going wrong for whatever reason, this puts you back to where you were before running it!
git merge (note no branch name) merges in new commits on the same branch; This is useful for collaborate projects, where someone else might update a branch.
Keeping up to date with a Remote
git fetch connects to your remote (Github), and makes a local copy of everything the remote system has! This is one of the few commands that actually needs internet to function.
Note, this does not change anything on your system. It does as the name implies, and just fetches it. Your local copies of branches remain at the commit you left them, so git fetch is always safe to run, and some tools run it automatically.
Pulling code from a remote + updating branches
git pull will contact the remote system, and apply changes from the remote branch to your local branch.
Behind the scenes, this is just running git fetch and then git merge. So, if you run git fetch and then try to work without internet, you can still get things done! Just use git merge with no branch name.
Pushing code to a remote
git push does this. By default it uses the same name, making this a short and simple one.
git push will fail if the push would cause a merge conflict on the remote system. This can happen if the remote branch has been modified since you branched off of it.
If this happens, you'll need to update your repository with git fetch or git pull , resolve the conflict, and try again
Git from VSCode
Handling Git operations from VS Code is normally a very streamlined operation, and it has good interfaces to do otherwise tricky operations.
Git Graph Plugin
This plugin provides some notable visualization tools that further improves Git handling in VS Code. We'll assume this is installed for the remainder of the tutorial here.
https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph
Install that first!
Git Sidebar
The icon on left side will open the git sidebar, which is the starting point for many git operations.
Opening it will provide some at a glance stuff to review.
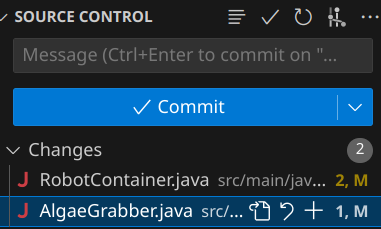
We can see a lot of useful things:
At the top we can see any uncommitted changes, and the file they belong to. We'll deal with this when reviewing changes and making new commits.
At the bottom (which might be folded down and labelled > Outline or > Graph), we can see our commit history for the current branch. The @main represents the current branch state, and icon represents the Origin (Github). If we're ahead or behind the origin, we can see it at a glance here.
Note, we also see main at the very bottom; That's always there, giving us our current branch at a glance.
Reviewing Changes + Making commits
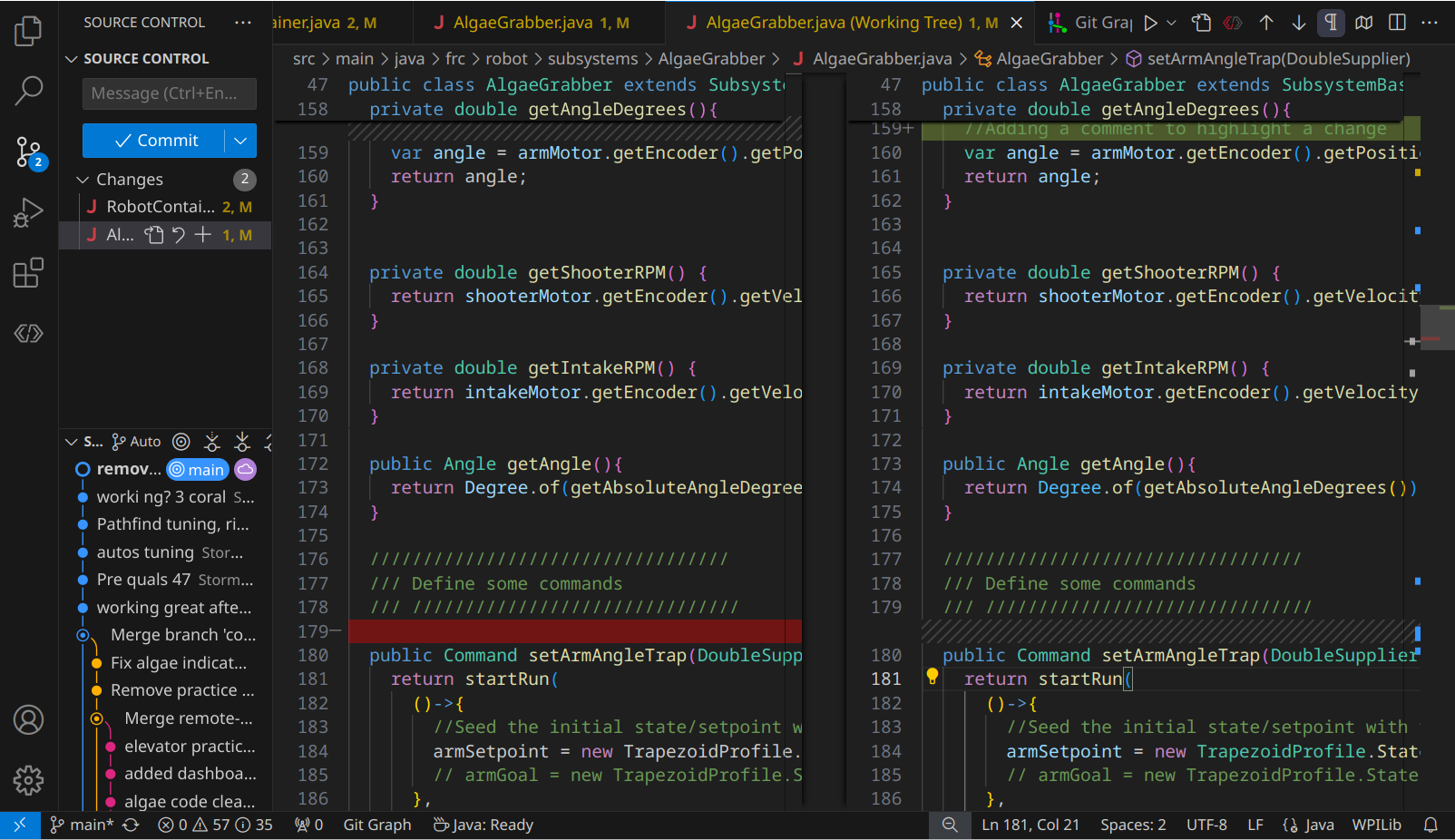
The easiest way to review changes is through the Git Sidebar: Just click the file,and you'll see a split view.
Changes will be shown in one of two ways. "Additions" are shown as a green highlight on the right side. On the left, you can see a ///////////////// placeholder; This helps align the code so that you can easily keep track of where stuff gets inserted!

Deletions look similar, but reversed. Left gets a red, right gets a placeholder.

Changes to part of a line are either an addition and removal, or a small highlighted change of the particular bits.
Note, you can actually type here! The right hand side is editable, allowing you to revise things if you see a change that's concerning. That side just represents the current state of the file in the workspace.
The left side is locked; This represents the prior state of the file, which can only be changed by adding more commits.
You can approve/confirm changes in a couple ways. The easiest is to simply use the "Stage Changes" button by the filename in the sidebar; This stages all changes in a particular file.
In many cases, it's helpful to handle them one by one: If you right click on a change (or selected text that includes one or more changes), you'll see some options besides the normal text editing ones
As the name implies, you can Stage changes if you want them, Unstage them (if you want to remove it from the commit you're putting together).
Note, you can also Revert it. In this case, reverting means that the change is gone! Added lines vanish, changed numbers go back to what they were, and reverting a deletion puts all the lines back! Be very careful here to not undo your work!
Note, that there's also a Revert/Discard Changes button too! Fortunately, this one checks with you. We'll rarely use it, but make sure to not hit it accidentally!
Once we've staged some changes, we'll any staged changes separate from any unstaged changes
You can commit with un-staged changes just fine, just be mindful! We'll touch on best practices later.
Once you've added all changes you want to include in the commit, just enter the message and click "Commit". Done!
Remote interactions + VS Code
VS Code has some useful built in operations to push or pull branches! These will typically pop up automatically, with the helpful options being
Push-> Does a standard pushPull-> Does a standard pullPublish Branch-> This is a normal Push, but applies to newly created local branches. This normally requires a couple other small steps, which this handles automaticallySync-> Don't use this one!
Be careful about the "Sync" button! Unlike other VSCode options, "Sync" will try to push and pull at the same time; However, in case of a merge conflict, it might try to resolve it using esoteric git operations behind the scenes. While this sometimes works, when something goes wrong fixing it properly is extremely challenging!
In almost all cases, using a git pull , verifying the merge, and then a git push is a better workflow!
Viewing the git tree with Git Graph
We're now looking at the Git Graph specific stuff, so make sure that's installed!
There's two ways to launch it. One is using VS Code's Command Palette, activated by CTRL+Shift+P then typing "View Git Graph" or "git log" to pull up this particular one.

The other is by clicking "Git Graph" along the bottom toolbar.
Both of these will take you to a good review interface, where you can see the status of many branches, the commit log, and how things merged and diverted! This is from our 2025 season code.
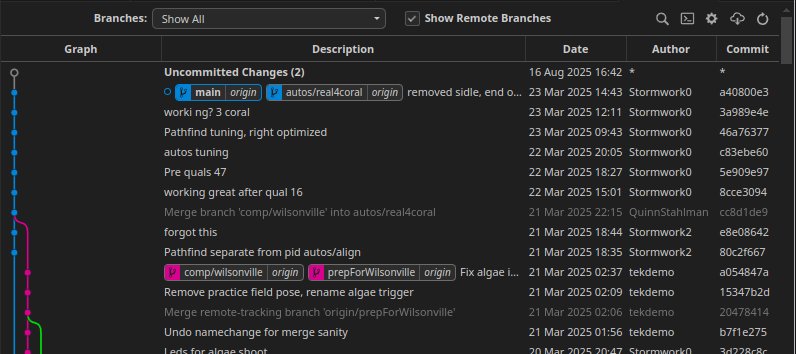
Just this interface provides a lot of value: You can easily see the commit history, how branches have diverged and been merged, and check to see what branches are ahead or behind of the origin.
If you click a commit, you get a more detailed status, but most notably what files were altered.
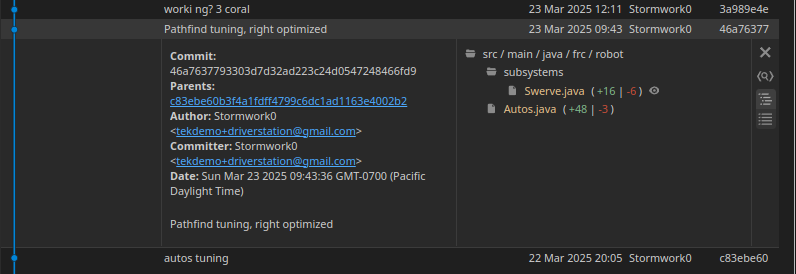
And, if you click the file in the commit details, it'll show you what that commit changed!
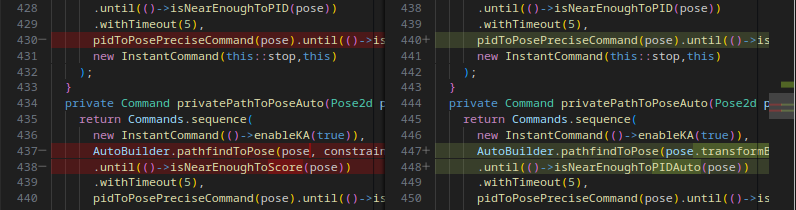
This is a very fast and effective way to look through your project and catch up on what's happening.
There's a lot of other value here if you click around, including being able to right click and checkout or switch to various branches!
VSCode's Git Terminal
VS Code's terminal often pops up during many other operations, but if you don't see it, you can access it through the menu.

Since we usually work on Windows, this will often open up a Powershell, which is usually sub-optimal for what we want to use a terminal for. Git Bash is usually nicer. You can change this with the Command Pallete (CTRL+Shift+P), and selecting Terminal: Select Default Profile.

If Bash is available, click it! Any new terminals will use the Git bash, which will have color, some at-a-glance git info, and generally more helpful all around.
Other Git tools
There's a lot of tools that interact with your Git repository, but it's worth being mindful about which ones you pick! A lot of tools wind up changing normal git operations into renamed or altered versions that do a lot of things at once. This can make learning it harder, and if something goes wrong, fixing the results can be extremely difficult. Stick to the basics until you know what's happening and you can properly judge if a new tool is worth using.
Making the best use of git in FRC
A typical FRC workflow
Creating the initial project setup:
git initto set up our new project.git add .to stage all the files in their blank, default state- Commit the code, using VSCode's interface or with the terminal
git commit -m "initial commit"
Doing the code work:
git branch featurebeingaddedto set up a new branch for your taskgit switch featurebeingaddedto select your new branch- Add the code
- Review the new code using VSCode, staging parts that are confirmed to work
- Commit the code (via Code or terminal)
- Repeat commits until done
Handling review and merging. Be mindful of local and remote branch states for this!
- Test and review your code! Make sure it works in the final state.
git fetchto ensure your git repo is aware of any changes.git merge origin/main --no-commit-> Bring in all new changes- Fix, test, review your code with all the new base project code.
git committo finalize the merge.git pushto push your branch with the merge completed.- Work with your maintainer (a mentor or veteran) to pull your new, validated changes back into
main!
Feature Branches
Branches are best when they're small, focused, and well defined.
A great workflow is using so called "topic branches" or "feature branches": In this workflow, a branch represents a feature you're adding, or a bug you're fixing. Once the feature is added and working, the branch is Done. You merge your branch back into the Main branch, and you can move onto another feature in a new branch!
By doing this, you keep each branch simple, easy to test, and easy to merge. It also helps prevent the issue of long-running branches; Where your code is isolated from a long time, and drifts apart from everyone else's code in main. That ends up with you not working on quite the same code base as other people, and you'll miss out on features, fixes that everyone else has, and they'll miss out on yours.
A good feature branch name also helps keep you as a programmer constrained to the task at hand.
Branch Naming
To facilitate "feature branch" convention, name your branches after feature itself, rather than the part of code it's affecting. Make sure that the branch name implies an "end state" at which point you can consider it Done and stop working on it.
As an example, some good initial branch names are add-far-shots, add-climb-routine, or fix-intake-stalling-issue. Since we're usually adding or fixing things, we can often omit that in the actual name leaving us with far-shots, climb-routine, intake-stall-issue), but it's helpful to always pretend it's there unless a clearer verb exists (like remove or adjust.
Early on, you might be tempted to name your branches after robot systems, like intake, shooter, or the like. But don't do this! The intake will always exist on the robot, so your branch has no clear end state!
Instead, name it something like intake-bringup. This provides an end-condition: Once the intake is brought up, functioning, and tested, the branch is done, and you can merge it back into main.
In some cases, it's helpful to indicate which part of the robot you're working on though: The optimal method is using subsystemname/feature. This is especially true of features relevant to various subsystems like bringup, which just yields intake/bringup, elevator/bringup, etc.
Merge other branches into yours
Merging is more useful than just sending your changes back to Main. You can use merging to keep up with other features that interact with the code you're working with.
As an example, let's say you're trying to bring up an Indexer system, which interacts with a Intake and a Shooter. During early development, you might see some branches like this
Intake and Shooter aren't done enough to merge back into main, but the indexer can't really be tested because you need to move it through the intake and shooter. But, you also don't want to actually do all that work yourself.
So, just merge the intake/bringup and shooter/bringup branches!
There you go! Now you can continue your work, using the preliminary work from the other branches. As they adjust and fix things, you can merge their code, and they could also merge yours into their branches before finally verifying 2 or 3 of these subsystems work properly.
There's a catch here: The branches in question might not be fully ready for you to pull them! It's always a good idea to talk to whoever's working on that code to make sure that it's in a state that's good to go. Sometimes they'll just need to adjust up one or two things, fix a variable/method name, or other times they might suggest you wait for some bigger cleanup or process fixes.
Merge main->Topic before Topic->main
Similar in concept to the above in some ways! By our process definitions, Main should always be in a good state, meaning you can pull it at any time. So, before declaring your branch Done and getting it in Main, go ahead and pull Main and test things first!
Now you can test the indexer in the full codebase without any risk of accidentally putting a bug in main, and any adjustments are part of the indexer/bringup branch like shown here
At long last, with everything fully integrated, we can finally get our changes back into main, knowing with confidence it works as expected.
PathPlanning Tools
Success Criteria
- Choose a PathPlanning tool
- Implement the Java framework for the selected tool
- Model the robot's physical parameters for your tool
- Drive a robot along a target trajectory using one of these tools
Followup to:
Auto Differential
Swerve Motion
The tools
https://docs.wpilib.org/en/stable/docs/software/pathplanning/index.html
https://choreo.autos/
https://pathplanner.dev/home.html
Understanding the concepts
Planning vs other method
Do you need path planning to make great autos? Maybe! But not always.
PathPlanning can give you extremely fast, optimized autos, allowing you to squeeze every fraction of a second from your auto. However, it can be challenging to set up, and has a long list of requirements to get even moderate performance.
Further Research
Pure Pursuit
Unlike "path planning" algorithms that attempt to define and predict robot motion, Pure Pursuit simply acts as a reactive path follower, as the name somewhat implies.
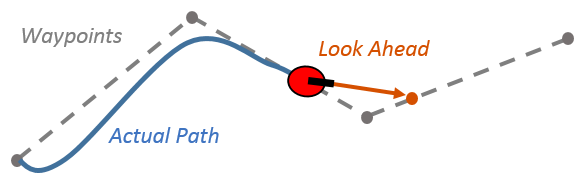
This algorithm is fairly simple and conceptually straightforward, but with some notable limitations. However, the concept is very useful for advancing simpler autos
Autopilot
Basic Odometry+Telemetry
Synopsis
Success Criteria
- Create a Widget on a dashboard to show the field
- Populate the Field with your robot, and one or more targets
- Utilize the Field to help develop a "useful feature" displayed on the Field
As a telemetry task, success is thus open ended, and should just be part of your development process; The actual feature can be anything, but a few examples we've seen before are
- showing which of several targets your code has deemed best, and react to it
- a path your robot is following, and where the bot is while following it
- The current Vision targets and where your bot is when seeing them
- A field position used as an adjustable target
- The projected path for a selected auto
- Inidcate proximity or zones "zones" for performing a task, such as the acceptable range for a shooting task or intaking process.
Odometry Fundamentals
Odometry is also known as Position Tracking. In FRC, this is generally regarded as knowing the position of your robot in the game field. It is most beneficial when combined with the robot to then have the robot move between positions on the field, and interact with other known positions.
Actually obtaining odometry depends on the design of the bot: Differential Drive Odometry or Swerve Odometry , and often involves vision systems via LimeLight Odometry or PhotonVision Odometry
This document is concerned with the prerequisite: Being able to actually view, compare, and validate positions using robot telemetry.
Odometry Telemetry
Telemetry for Odometry revolves around the Field2D object. Both Glass and Elastic can display the Field2D object as a game field on the dashboard, including associated robot positions and any secondary objects.
In general, Glass is the superior option for most programming tasks and development, allowing easier customization to help reduce clutter and provide clarity between objects.
The WPILib Docs are excellent at helping demonstrate many of these examples:
https://docs.wpilib.org/en/stable/docs/software/dashboards/glass/field2d-widget.html
Pose
In Robots, a Pose represents a specific location and state of a robot's actuator. Within the context of odometry, a pose represents the robot's location on a 2D plane. In most cases, this means the location on the game field.
In order to represent such a state, we need 3 things: The X position, the Y position, and a rotation.
In WPILib, this is handled by the Pose2d object, which can be provided to and returned from many utilities interacting with the robot position, including drivetrain path planning, vision, simulation, and telemetry.
Field2D Basics
The Field2D object in WPILib contains a number of utilities for keeping tabs on odometry. It can be added with just a couple lines.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
//We only want to send the actual Field object _once_,
//so we often do it in the constructor. Changes will be
//sent automatically as the Field2d object itself is updated.
//Preferred: Set the NetworkTables name explicitly,
//and give it a unique, descriptive name
SmartDashboard.putData("ChassisField",field);
// This form uses the default name "Field" as the key.
// Not recommended in most cases
//SmartDashboard.putData(field);
}
}
This creates a blank, empty field, with your robot position, probably at (0,0) in the bottom left corner, on the blue side of the field.
Meaningfully updating the robot pose is out of scope, and differs by drivetrain type; However, the basic gist is
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
//Set up an odometry object to track our robot
DifferentialDrivePoseEstimator odometry=new DifferentialDrivePoseEstimator(
/* Complex constructor parameters; not relevant*/
)
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
}
public void periodic(){
//Read the odometry object and set the pose. //Reference only
field.setRobotPose(odometry.getPoseMeters());
// Or, we can just set it manually for testing.
field.setRobotPose(new Pose2d(2.7,3.1, new Rotation2d(Math.PI/2.0) ));
}
}
Now, when we open our Field2D widget in Glass, we'll see that our robot is at a new position. If we fully implemented our Pose Estimator object, we'd see that this provides realtime tracking of our position.
A .getRobotPose() also exists, but tends to be less useful in practice, as most classes that will interact with the Robot and Field will likely have access to the Odometry object directly.
Note, that the Field2d object we create is a unique reference, with it's own unique local data; only the NetworkTables key might have overlap when using default keys. This means if we want to properly share a Field across multiple classes, we either need to fetch the NetworkTables data and copy it over, create a single Field object in RobotContainer and pass it to, or create a DriverField object as a Singleton that can facilitate a single object.
Displaying Useful Targets
Where Field2d objects really shine is in adding supplemental information about other field objects. The utility varies by game, but it's great for showing a variety of things such as
- Targets/objectives
- Nearest/best target
- Nearest game piece (detected by vision systems)
These can be done using the getObject(name) method; This grabs the named object from the field, creating it if it doesn't already exist.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
}
public void periodic(){
//Can provide any number of pose arguments
field.getObject("GamePieces").setPoses(
new Pose2d(1,1),
new Pose2d(1,2),
new Pose2d(1,3),
);
//You can also pass a single List<Pose2d>
//if you have a list of poses already
field.getObject("BestGamePiece").setPose(
new Pose2d(1,2)
);
}
}
Note It's worth considering that for objects that never move, you could set objects once in the constructor, and they work fine. However, if the user accidentally moves them in the UI, it creates a visual mis-match between what the code is doing and what the user sees. As a result, it's often better to just throw it in a Periodic.
Field2d + User Input
A niche, but very useful application of field objects is to get precise driver feedback on field location data. This can be done using the following code setup:
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
//Set the pose exactly once at boot
field.getObject("DriverTarget").setPose(
new Pose2d(1,2)
);
}
public Command aimAtCustomTarget(){
return run(()->{
var target=field.getObject("DriverTarget").getPose();
//Do math to figure out the angle to target
//Set your drivetrain to face the target
};
}
public void periodic(){
//No setting DriverTarget pose here!
};
}
In this case, we take advantage of the "set once" approach in constructors; The drivers or programmers can modify the position, and then we now read it back into the code.
This can be very useful for testing to create "moving targets" to test dynamic behavior without having to drive the bot. It can also help you create "simulation" poses for testing math relating to Pose2D objects.
is especially true for simulation, as this allows you quickly test pose-related functions and makes sure that things happen how you expect.
One practical application is match-specific targets for cooperating with allies. An example is in 2024 Crescendo: a common game tactic was to "pass" rings across the field, by shooting to an open area near where your allies would be. However, since the game pieces can get stuck in/on robots, and different robots have different intakes, and each ally has different sight lines, making the ideal pass target unknown until the actual match is about to start. An adjustable target let the alliance sort it out before a match without having to change the code.
Displaying Paths
When doing path-planning for drivetrains, it's often helpful to display the full intended path, rather than a lot of individual poses.
class Drivetrain extends SubsystemBase{
Field2D field = new Field();
public Drivetrain(){//constructor
SmartDashboard.putData("ChassisField",field);
//Set the pose exactly once at boot
field.getObject("DriverTarget").setPose(
new Pose2d(1,2)
);
}
public Command buildAuto1(){
var trajectory=// Get the trajectory object from your path tool
field.getObject("autoTrajectory").setTrajectory(trajectory);
return run(()->{
//draw the rest of the owl
};
}
}
In this use case, the work will likely be done inside your Auto class after selecting the appropriate one.